
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- DI
- 일급컬렉션
- java
- 자바의정석
- 스파르타코딩클럽
- 싱글톤패턴
- 항해99
- 스프링컨테이너
- 서버사이드렌더링
- 클라이언트사이드렌더링
- Spring
- 더티채킹
- SOLID
- publicapi
- 9기
- privateapi
- 지네릭스
- IoC
- 애너테이션
- 정적중첩클래스
- refreshtoken
- 비정적중첩클래스
- 항해99 9기
- 인프콘
- 다형성
- bean
- 인수테스트
- github actions
- 변경감지
- Velog
- Today
- Total
멈재
[Spring/JPA] JPA flush, 편하게 써도 되는걸까 본문
최근에 스터디원 중 한 분이 JPA flush를 공유하는 과정에서 잘 이해되지 않는 부분이 있었고, 해당 주제로 의견을 나눈 것이 있었다.
질문이 자세하게 기억나지는 않지만 나도 내 생각과 의견을 말하면서 명확하지 않은 부분이 존재했었다.

문제 상황에 바로 들어가기보다 플러시를 이해하기 위해 영속성 컨텍스트(1차 캐시)의 개념을 간략히 리마인드 해보려고 한다.
영속성 컨텍스트는 영속 엔티티 인스턴스의 집합으로 컨텍스트 내에서 엔티티 인스턴스와 해당 라이프 사이클이 관리된다. 엔티티 매니저 API는 엔티티 인스턴스를 생성 및 제거하고, 기본 키로 엔티티를 찾고, 엔티티에 대해 쿼리하는데 사용한다.
An EntityManager instance is associated with a persistence context. A persistence context is a set of entity instances in which for any persistent entity identity there is a unique entity instance. Within the persistence context, the entity instances and their lifecycle are managed. The EntityManager API is used to create and remove persistent entity instances, to find entities by their primary key, and to query over entities.
출처: https://docs.oracle.com/javaee/7/api/javax/persistence/EntityManager.html
쉽게 말해 영속성 컨텍스트는 엔티티를 영구 저장하는 저장소이고, 엔티티 매니저를 통해 엔티티를 관리할 수 있다고 설명할 수 있다.
영속성 컨텍스트는 엔티티를 관리한다고 말했는데, 엔티티의 상태에 따라 영속성 컨텍스트에서 관리되는 형태가 다르다.
아래 이미지는 행위에 따른 엔티티의 생명 주기 이미지이다.
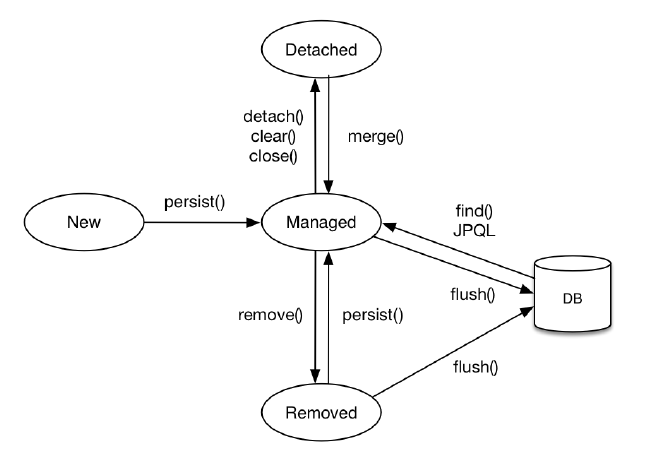
이미지상으로는 네 가지의 상태가 존재하지만 그 중에서 비영속 상태(new/transient)와 영속 상태(managed)만 알아보도록 하겠다.
비영속 상태
비영속 상태란 엔티티가 영속성 컨텍스트와 전혀 관계없는 상태로, 단순히 객체만 생성한 상태를 나타낸다.
Todo todo = new Todo("플러시 포스팅하기");
영속 상태
영속 상태란 영속성 컨텍스트가 엔티티를 관리되는 상태를 나타낸다.
EntityManager.persist(todo);
엔티티의 상태와 더불어 영속성 컨텍스트는 다음과 같은 특징들이 있다.
- 엔티티를 식별자 값(@Id)으로 구분한다.
- 영속성 컨텍스트에 영속 상태가 된다고 해도 곧바로 데이터베이스에 반영되지는 않는다.
- 영속성 컨텍스트에 최초로 등록될 때 엔티티의 최초 상태를 복사해 두어 저장하게 되고 이를 '스냅샷'이라고 한다.
이제 진짜 플러시
플러시는 영속성 컨텍스트에 보류 중(pending)인 모든 변경 사항을 데이터베이스에 반영하는 것이다.
그렇다면 이 플러시는 언제 동작하는 것일까
- EntityManager.flush를 직접 호출
- 트랜잭션 커밋 시점에 flush가 자동 호출
- JPQL 쿼리 실행 직전에 자동 호출
위 세 가지 상황에서 플러시가 동작되게 되고, 이 중에서 세 번째 상황인 JPQL 쿼리 실행 직전에 자동 호출되는 상황을 이야기해보려고 한다.
JPQL은 엔티티 객체를 대상으로 쿼리를 날리는 SQL을 추상화한 객체 지향 쿼리 언어 중 하나이다.
SQL을 추상화했기 때문에 특정 데이터베이스 벤더에 의존하지 않고, 결과적으로 SQL로 변환되어 실행된다.
예시에서 사용될 Todo 엔티티는 다음과 같다.
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString @Getter
public class Todo {
@Id @GeneratedValue
private Long id;
private String content;
public Todo(String content) {
this.content = content;
}
}
간단한 예시를 들어보려고 한다.
예시에서 중점적으로 봐야 하는 내용은 flush가 호출되어 데이터베이스에 쿼리가 나가는지를 확인하는 것이다.
앞으로 설명한 예시를 요약하면 다음과 같다.
1. 영속 상태로 만든 엔티티를 em.find로 조회
=> em.find()로 조회하는 예시로 데이터베이스에서 바로 조회를 하지 않는다.
영속성 컨텍스트의 1차 캐시에 찾으려는 엔티티가 존재하는지 확인해서 존재한다면 1차 캐시에 존재하는 엔티티를 가져오고, 존재하지 않는다면 데이터베이스에 실제 쿼리를 날려 엔티티를 1차 캐시에 저장하고 가져오게 된다.
2. 영속 상태로 만든 엔티티를 JPQL(em.createQuery)로 조회
=> em.createQuery로 조회하는 예시로 flush를 수행하고 데이터베이스에서 바로 조회해온다.
따라서 JPQL 쿼리 실행 직전에 보류 중인 변경 사항을 데이터베이스에 반영하고, 영속성 컨텍스트를 거치지 않고 데이터베이스에서 바로 조회를 한다.
참고로 JPQL로 데이터베이스에 SELECT 했을 때, 조회한 엔티티 식별자가 영속성 컨텍스트의 1차 캐시에 존재하지 않을 경우 찾아온 엔티티를 영속성 컨텍스트에 등록한다.
( 본 예시에서는 FlushMode의 기본 값인 FlushModeType.AUTO를 기준으로 설명하고 있습니다. )
1. 영속 상태로 만든 엔티티를 엔티티 매니저로 조회
영속성 컨텍스트의 특징을 설명하면서 영속성 컨텍스트에 특정 엔티티가 영속 상태가 된다 해도 곧바로 데이터베이스에 반영하지 않는다고 했다. 이 말은 즉 INSERT 쿼리가 실행되지 않음을 의미한다.
아래 코드를 보자.
@Test
@DisplayName("영속 상태로 만든 엔티티를 엔티티 매니저로 조회한다.")
void 엔티티_매니저로_조회() {
Todo todo1 = new Todo("할일-1");
Todo todo2 = new Todo("할일-2");
Todo todo3 = new Todo("할일-3");
em.persist(todo1);
em.persist(todo2);
em.persist(todo3);
Todo findTodo = em.find(Todo.class, todo1.getId());
System.out.println("[Spring Jpa] => findTodo = " + findTodo);
}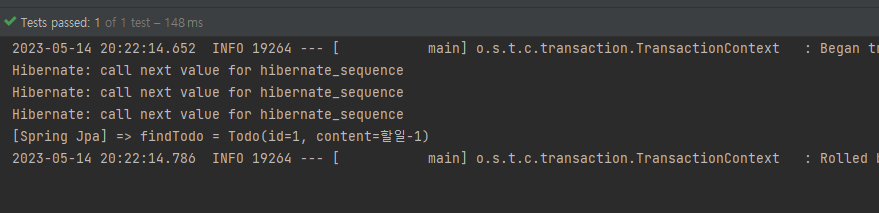
영속 상태로 만들었지만 실제 데이터베이스에 INSERT 쿼리가 나가지 않은 것을 확인할 수 있다.
당연하게도 JpaRepository를 이용해도 그 결과는 마찬가지이다.
JpaRepository의 구현 클래스인 SimpleJpaRepository에 save 메서드를 보게 되면 비영속 상태인 경우 persist로 동작되도록 구현되어 있다.
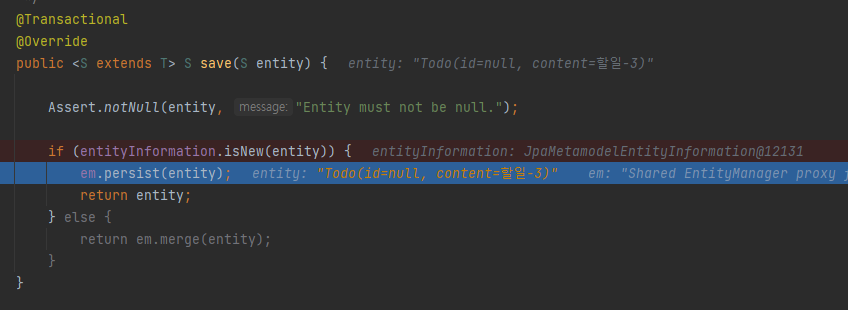
따라서 들어온 엔티티가 비영속 상태인지를 확인한 다음 비영속 상태라면 영속 상태로 만들어주고, 아니라면 merge 명령을 통해 준영속 상태인 엔티티를 영속 상태로 변경하게 된다.
@Test
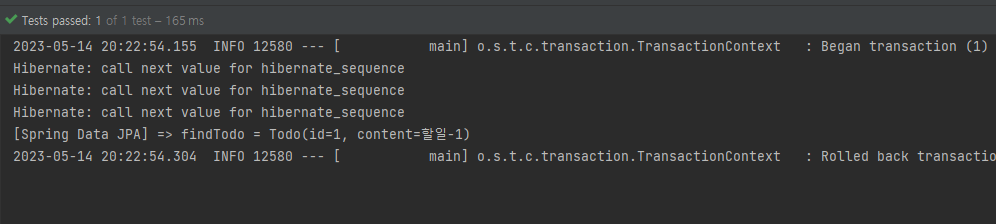
@DisplayName("Spring Data JPA도 마찬가지로 flush가 나가지 않는다.")
void DATA_JPA도_flush가_나가지_않는다() {
Todo todo1 = new Todo("할일-1");
Todo todo2 = new Todo("할일-2");
Todo todo3 = new Todo("할일-3");
Todo saveTodo1 = todoRepository.save(todo1);
Todo saveTodo2 = todoRepository.save(todo2);
Todo saveTodo3 = todoRepository.save(todo3);
Todo findTodo = em.find(Todo.class, saveTodo1.getId());
System.out.println("[Spring Data JPA] => findTodo = " + findTodo);
}
2. 영속 상태로 만든 엔티티를 JPQL로 조회
반면 JPQL의 경우에는 어떨까
플러시가 실행되는 경우는 JPQL 쿼리 실행 직전에 실행된다고 설명했다.
따라서 아래 코드를 실행하게 되면,
1. INSERT 쿼리가 실행되어야 하고,
2. persist 이후, JPQL 이전에 println이 실행
되어야 한다.
본 예시에서는 FlushMode의 기본 값인 FlushModeType.AUTO를 기준으로 설명하고 있습니다.
@Test
@DisplayName("영속 상태로 만든 엔티티를 JQPL로 조회한다.")
void JPQL로_조회() {
Todo todo1 = new Todo("할일-1");
Todo todo2 = new Todo("할일-2");
Todo todo3 = new Todo("할일-3");
em.persist(todo1);
em.persist(todo2);
em.persist(todo3);
System.out.println("====> is call before JPQL");
Todo findTodo = em.createQuery("select t from Todo t where id = :id", Todo.class)
.setParameter("id", todo1.getId()).getSingleResult();
System.out.println("[JPQL] => findTodo = " + findTodo);
}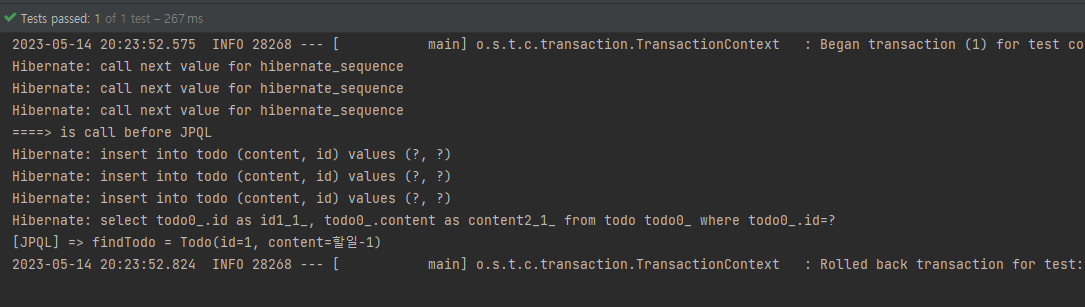
결과는 예상대로 println이 JPQL이 실행되기 전에 수행되었다.
아마 이 내용들은 JPA를 사용해 본 사람이라면 대부분 아는 내용이고, 만약 문제가 발생하더라도 금방 알아차리기 쉬울 것이다.
그러나 아래의 예시는 어떠한 결과가 나올까
1. 엔티티를 영속 상태로 만든다. (persist)
2. JPQL update 실행
3. JPA EntityManager.find
4. JPQL SELECT
코드는 다음과 같다.
@Test
@DisplayName("1) 엔티티 save(persist) -> 2) JPQL update -> 3) JPA findOne -> 4) JPQL findOne")
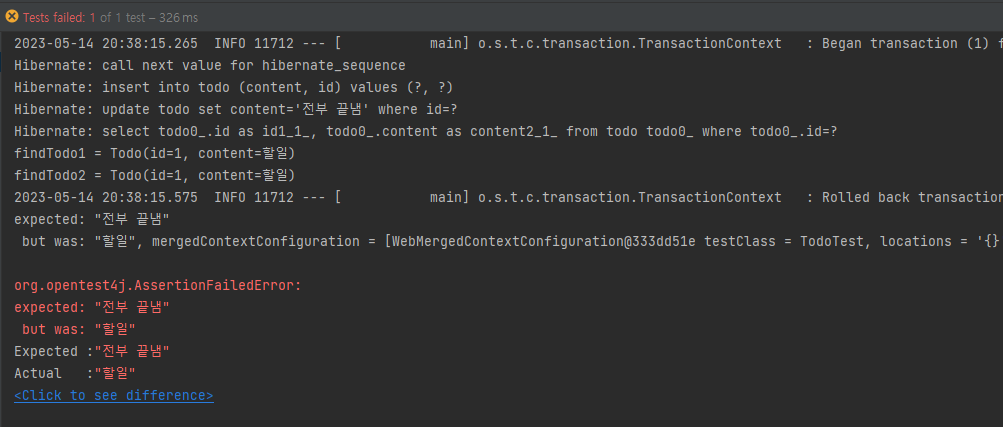
void 복잡한_조회와_변경() {
// 1) 3개의 엔티티 persist
Todo todo = new Todo("할일");
Todo saveTodo = todoRepository.save(todo);
// 2) JPQL Update
em.createQuery("update Todo t set t.content = '전부 끝냄' where t.id = :id")
.setParameter("id", saveTodo.getId())
.executeUpdate();
// 3) JPA findOne
Todo findTodo1 = em.find(Todo.class, saveTodo.getId());
// 4) JPQL findOne
Todo findTodo2 = em.createQuery("select t from Todo t where t.id = :id", Todo.class)
.setParameter("id", saveTodo.getId())
.getSingleResult();
System.out.println("findTodo1 = " + findTodo1);
System.out.println("findTodo2 = " + findTodo2);
assertThat(findTodo2.getContent()).isEqualTo("전부 끝냄");
}
과연 findTodo1과 findTodo2는 어떠한 결과가 나올까
...
...
...
...
...
...
...
...
???
분명 JPQL 쿼리가 실행되기 전에 플러시가 실행되어 데이터베이스에 저장이 되고, UPDATE가 나간 것도 확인했는데 검증에 실패하고, 변경된 결과를 출력으로 얻지 못했다.
왜 그럴까?
그 이유는, 영속성 컨텍스트에 persist 되어 올라간 Todo가 존재하기 때문이다.
JPQL에 의해 persist와 INSERT가 되고, 그 이후에 update 쿼리가 실행되었다 해도 영속성 컨텍스트에는 여전히 update 되기 이전의 내용인 '할일'이 있게 된다.
따라서 UPDATE 된 내용이 영속성 컨텍스트에는 반영되지 않아 '전부 끝냄'이 아닌 '할일'이 나오게 된 것이다.
그렇다면 JPQL로 조회한 것은 왜 실패한 것일까
JPQL에서 조회 방식은 다음의 과정을 거치게 된다.
1. JPQL로 조회하면 데이터베이스에 우선적으로 조회한다.
2. 조회한 값을 영속성 컨텍스트에 저장을 시도한다.
3. 저장을 시도할 때 해당 엔티티의 식별자가 영속성 컨텍스트에 존재한다면 데이터베이스에서 조회해온 신규 데이터를 버려지고 영속성 컨텍스트에 있는 엔티티가 반환된다. 반대로, 영속성 컨텍스트에 엔티티의 식별자가 존재하지 않는다면 가져온 결과를 기반으로 엔티티 객체를 생성해서 영속성 컨텍스트에 저장하게 된다.
이러한 이유들로 생각했던 검증 결과와 원하는 출력을 얻지 못했던 것이다.
만약 정상적인 흐름으로 변경하고 싶은 거라면,
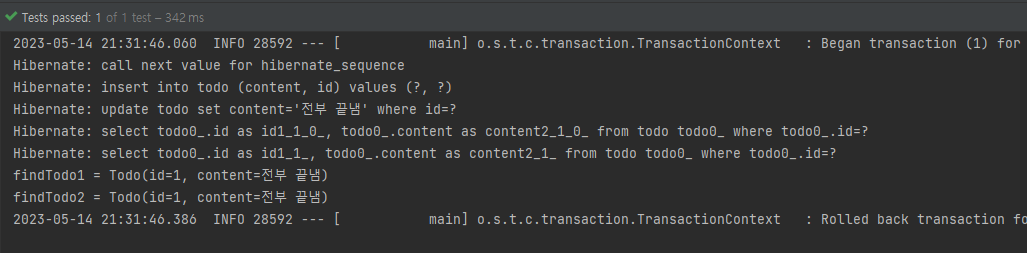
영속성 컨텍스트를 비우는 작업(EntityManager.clear())을 명시적으로 해주게 되면 조회한 엔티티의 결과가 '전부 끝냄'이 나오게 된다.
@Test
@DisplayName("1) 엔티티 save(persist) -> 2) JPQL update -> 3) JPA findOne -> 4) JPQL findOne")
void 복잡한_조회와_변경_문제X() {
// 1) 3개의 엔티티 persist
Todo todo = new Todo("할일");
Todo saveTodo = todoRepository.save(todo);
// 2) JPQL Update
em.createQuery("update Todo t set t.content = '전부 끝냄' where t.id = :id")
.setParameter("id", saveTodo.getId())
.executeUpdate();
em.clear();
// 3) JPA findOne
Todo findTodo1 = em.find(Todo.class, saveTodo.getId());
// 4) JPQL findOne
Todo findTodo2 = em.createQuery("select t from Todo t where t.id = :id", Todo.class)
.setParameter("id", saveTodo.getId())
.getSingleResult();
System.out.println("findTodo1 = " + findTodo1);
System.out.println("findTodo2 = " + findTodo2);
assertThat(findTodo1.getContent()).isEqualTo("전부 끝냄");
assertThat(findTodo2.getContent()).isEqualTo("전부 끝냄");
}
따라서 변경 작업은 대부분의 경우 쿼리를 직접 날리기보다 변경 감지 기능을 활용하는 것이 영속성 컨텍스트와의 일관성을 유지할 수 있고, 영속성 컨텍스트의 1차 캐시 기능을 적절하게 사용할 수 있게 된다.
마치며
영속성 컨텍스트에 대해 어느 정도 알고 있다고 생각했는데 알고 있다는 착각을 하고 있었던 것 같다.
틈틈이 부족한 부분들을 채워나가야겠다.
이번 포스팅에서는 기본적인 플러시 개념들을 설명했지만, 다음번에는 아직 잘 모르겠거나 추가하고 싶은 부분들을 '심화 편'이라는 이름으로 다뤄볼까 한다.
- flush SQL 순서
- JPQL로 조회해온 엔티티는 왜 버려지는지 (REPETABLE READ)
- 왜 id를 통한 조회가 아닌 경우(findByContent)에는 영속성 컨텍스트의 1차 캐시를 거치지 않을까
- JPA의 영속성 컨텍스트과 하이버네이트의 세션 (OSIV)
- Transactional 애너테이션의 readOnly
- 준영속 상태 엔티티를 조심해야 한다
참고
'JAVA & Spring & JPA' 카테고리의 다른 글
| [Spring] How to use @Transactional well? (부제: Spring Transactional 주의점) (0) | 2023.06.25 |
|---|---|
| [JAVA] 제네릭의 공변과 불공변 그리고 타입 소거 (0) | 2023.06.04 |
| [JAVA] 중첩 클래스, 중첩 클래스의 문단속 (0) | 2023.04.29 |
| [디자인 패턴] 싱글턴 패턴, 내가 알던 싱글턴이 아니야! (0) | 2023.04.18 |
| [JAVA] 자바 애너테이션과 활용 예시 (Annotation) (0) | 2023.03.26 |



