
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- DI
- privateapi
- refreshtoken
- bean
- publicapi
- 인프콘
- 서버사이드렌더링
- 항해99 9기
- 애너테이션
- IoC
- 다형성
- Spring
- 항해99
- 싱글톤패턴
- 스프링컨테이너
- 클라이언트사이드렌더링
- 자바의정석
- 비정적중첩클래스
- 변경감지
- 9기
- Velog
- 일급컬렉션
- 지네릭스
- github actions
- 정적중첩클래스
- SOLID
- 스파르타코딩클럽
- 더티채킹
- 인수테스트
- java
- Today
- Total
멈재
[DB] MySQL 트랜잭션 격리 수준 살펴보기 본문
트랜잭션이란
- 하나의 처리를 안전하게 처리하도록 보장해주는 것
- 작업의 완전성을 보장해주는 것
풀어쓰면 데이터베이스의 상태를 변경하는 논리적인 작업 단위를 전부 반영하거나 아무것도 적용하지 않아야 한다는 것을 보장한다.
즉, 모두 처리하지 못할 경우에 작업의 일부분만 적용되는 현상(Partial Update)이 발생하지 않게 하는 기능이다.
🧐 용어 설명
*상태를 변경한다
INSERT, UPDATE 등의 작업으로 저장된 데이터의 상태를 수정, 삭제 등의 작업을 통해 변경하는 것을 의미
*작업 단위
하나의 처리를 위해 수행되는 SQL 질의어
*하나의 처리
'하나의 처리’라고 해서 여러 개의 쿼리를 의미하는 것이 아닌 하나의 쿼리가 있든 두 개 이상의 쿼리가 있든 관계없이 논리적인 작업 자체를 의미
예를 들어 멈재가 깨비에게 금액을 송금하는 상황이 있다고 가정해보자
그러면 처리해야 할 기능은 송금일 것이고 송금을 하기 위한 작업들은 다음과 같다.
- 멈재는 송금할 금액을 가지고 있어야 한다.
- 멈재의 통장에서 송금할 금액만큼 출금한다.
- 깨비의 통장에 해당 금액을 송금한다.
이처럼 하나의 처리를 위해 여러 과정들이 존재하고 이러한 과정들을 하나의 처리로 묶는 것이 트랜잭션이다.
그런데 만약 하나의 과정에서라도 문제가 발생하게 되면 모든 작업을 원상태로 복구하고, 정상적인 과정을 거친다면 결과를 반영하게끔 트랜잭션이 보장해주게 된다. (커밋 & 롤백)
트랜잭션의 특성
트랜잭션은 다음 4가지의 특성(ACID)을 보장해야 한다.
원자성(A, Atomicity)
트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공하거나 모두 실패해야 한다. (All or Nothing)
일관성(C, Consistency)
모든 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야 한다.
예를 들어, 데이터베이스에서 정한 무결성 제약 조건을 항상 만족해야 한다.
격리성(I, Isolation)
동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다.
예를 들어 동시에 같은 데이터를 수정하지 못하도록 해야 한다.
격리성은 동시성과 관련된 성능 이슈로 인해 트랜잭션 격리 수준(Isolation level)을 선택할 수 있다.
지속성(D, durability)
트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다.
중간에 시스템에 문제가 발생해도 데이터베이스 로그 등을 사용해서 성공한 트랜잭션 내용을 복구해야 한다.
트랜잭션은 원자성, 일관성, 지속성을 보장하는데, 격리성은 완벽히 보장하려면 트랜잭션을 순서대로 실행하도록 해야 한다.
하지만 이렇게 처리하면 동시 처리 성능이 나빠지게돼서 ANSI 표준은 트랜잭션의 격리 수준을 4단계로 나누어 정의했다.
MySQL의 트랜잭션 격리 수준
트랜잭션의 격리 수준은 여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지를 결정하는 것이다.
InnoDB는 SQL-92 표준에서 제공하는 4가지 격리 수준을 제공한다.
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ (MySQL InnoDB의 기본 격리 수준)
- SERIALIZABLE
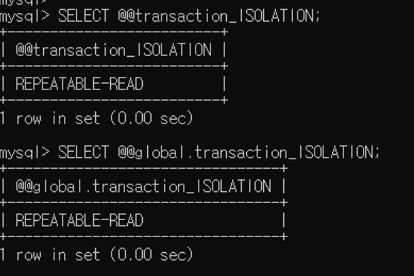
SET TRANSACTION 구문을 실행해서 하나의 세션 또는 모든 클라이언트 연결에 격리 수준을 변경할 수 있다.
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL [level]
level: { REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE }mysql> SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@transaction_ISOLATION;
+-------------------------+
| @@transaction_ISOLATION |
+-------------------------+
| SERIALIZABLE |
+-------------------------+
1 row in set (0.00 sec)
mysql> SELECT @@global.transaction_ISOLATION;
+--------------------------------+
| @@global.transaction_ISOLATION |
+--------------------------------+
| REPEATABLE-READ |
+--------------------------------+
1 row in set (0.00 sec)
트랜잭션 격리 수준에 따라 발생하는 문제점
격리 수준이 위쪽에서 아래쪽으로 내려갈수록 격리 정도가 높아지고 동시성 처리 성능도 떨어진다.
격리 수준이 높아질수록 MySQL 서버의 처리 성능이 많이 떨어질 거라 생각하지만, SERIALIZABLE이 아니라면 큰 성능차이는 없다. - Real MySQL (p176)
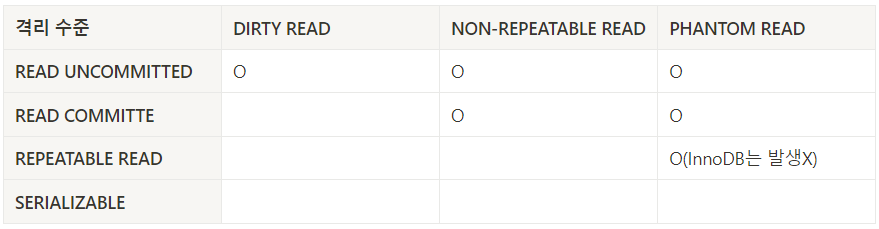
SQL-92 또는 SQL-99 표준에 따르면 REPEATABLE READ 격리 수준에서 PHANTOM READ가 발생할 수 있지만 InnoDB에서는 독특상 특성으로 인해 발생하지 않는다. (밑에서 설명)
아래 예시들은 모두 오토 커밋을 끈(AUTO_COMMIT = OFF) 상태로 진행한다.
mysql> SET AUTOCOMMIT = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES WHERE VARIABLE_NAME = 'AUTOCOMMIT';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.02 sec)
예제 테이블 및 샘플 데이터
CREATE TABLE study (
id BIGINT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
max BIGINT(20) NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO study(name, max) VALUES ("CS 스터디", 5);
INSERT INTO study(name, max) VALUES ("알고리즘 스터디", 4);
INSERT INTO study(name, max) VALUES ("이펙티브 자바 스터디", 7);
INSERT INTO study(name, max) VALUES ("도메인 주도 개발 시작하기 스터디", 4);
READ UNCOMMITTED
트랜잭션의 변경 내용이 커밋이나 롤백 여부와 관계없이 다른 트랜잭션에 보이게 된다.
1. 두 개의 세션을 연결하고 각 세션을 READ UNCOMMITTED로 변경

2. 왼쪽 세션에서 트랜잭션을 시작하고 하나의 데이터를 추가(INSERT)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO study(name, max) VALUES("Real MySQL 8.0 스터디", 3);
Query OK, 1 row affected (0.00 sec)
3. 우측 세션에서 해당 테이블을 조회
왼쪽 세션에서 커밋 또는 롤백을 하지 않았지만 추가한 데이터가 보이게 된다. (문제점)
mysql> SELECT * FROM study;
+----+----------------------------------+-----+
| id | name | max |
+----+----------------------------------+-----+
| 1 | CS 스터디 | 5 |
| 2 | 알고리즘 스터디 | 4 |
| 3 | 이펙티브 자바 스터디 | 7 |
| 4 | 도메인 주도 개발 시작하기 스터디 | 4 |
| 5 | Real MySQL 8.0 스터디 | 3 |
+----+----------------------------------+-----+
5 rows in set (0.00 sec)
4. 왼쪽 세션에서 롤백을 수행하여 트랜잭션을 종료
mysql> ROLLBACK;
Query OK, 0 rows affected (0.01 sec)
5. 우측 세션에서 해당 테이블을 다시 조회
mysql> SELECT * FROM study;
+----+----------------------------------+-----+
| id | name | max |
+----+----------------------------------+-----+
| 1 | CS 스터디 | 5 |
| 2 | 알고리즘 스터디 | 4 |
| 3 | 이펙티브 자바 스터디 | 7 |
| 4 | 도메인 주도 개발 시작하기 스터디 | 4 |
+----+----------------------------------+-----+
4 rows in set (0.00 sec)
이처럼 특정 트랜잭션에서 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있게 되는 현상을 더티 리드(DIRTY READ)라고 한다.
이러한 문제가 발생하는 READ UNCOMMITTED는 문제가 많은 격리 수준이라 사용하지 않는 것을 권장한다.
READ COMMITED
READ COMMITED는 오라클 데이터베이스의 기본 격리 수준으로 커밋이 이루어진 데이터만 다른 트랜잭션에서 조회가 가능하다.
따라서 이 레벨에서는 READ UNCOMMITTED에서 발생할 수 있는 문제였던 더티 리드 같은 현상이 발생하지 않는다.
1. 두 개의 세션을 연결하고 각 세션을 READ COMMITTED로 변경

mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@transaction_ISOLATION;
+-------------------------+
| @@transaction_ISOLATION |
+-------------------------+
| READ-COMMITTED |
+-------------------------+
1 row in set (0.00 sec)
2. 왼쪽 세션에서 트랜잭션을 시작하고 name이 ‘CS 스터디’인 데이터의 제목을 ‘고급 CS 스터디’로 변경
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> UPDATE study SET name = '고급 CS 스터디' WHERE name = 'CS 스터디';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
3. 우측 세션에서 해당 테이블을 조회
커밋을 수행하지 않았기 때문에 다른(왼쪽) 세션에서 변경한 데이터가 아닌 변경하기 이전의 데이터를 읽어오게 된다.
mysql> SELECT * FROM study;
+----+----------------------------------+-----+
| id | name | max |
+----+----------------------------------+-----+
| 1 | CS 스터디 | 5 |
| 2 | 알고리즘 스터디 | 4 |
| 3 | 이펙티브 자바 스터디 | 7 |
| 4 | 도메인 주도 개발 시작하기 스터디 | 4 |
+----+----------------------------------+-----+
4 rows in set (0.00 sec)
4. 왼쪽 세션에서 커밋을 한 후 오른쪽 세션에서 테이블을 다시 조회
READ COMMITTED이기 때문에 커밋을 하고 나면 다른 세션에서 변경한 데이터를 조회하게 된다.
mysql> SELECT * FROM study;
+----+----------------------------------+-----+
| id | name | max |
+----+----------------------------------+-----+
| 1 | 고급 CS 스터디 | 5 |
| 2 | 알고리즘 스터디 | 4 |
| 3 | 이펙티브 자바 스터디 | 7 |
| 4 | 도메인 주도 개발 시작하기 스터디 | 4 |
+----+----------------------------------+-----+
4 rows in set (0.00 sec)
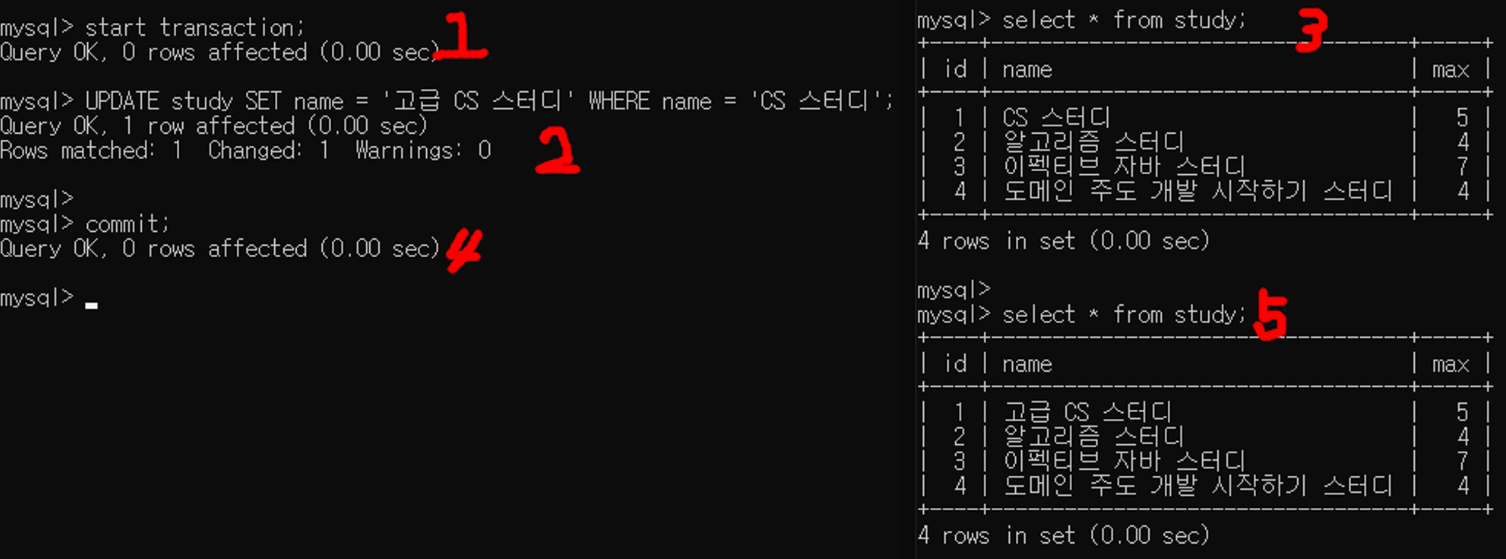
문제가 얼추 해결된듯하지만 READ COMMITTED에서는 하나의 트랜잭션에서 조회(SELECT)할 때 일관된 데이터를 반환하지 않는 NON-REPEATABLE READ 문제가 발생한다.
요약한 시나리오는 다음과 같다.
- 왼쪽 세션에서 트랜잭션을 시작하고 ‘자바의 정석 스터디’를 조회 >> 결과 0건
- 우측 세션에서 트랜잭션을 시작하고 이름이 ‘이펙티브 자바 스터디’를 ‘자바의 정석 스터디’로 변경하고 커밋
- 다시 왼쪽 세션에서 ‘자바의 정석 스터디’를 조회 >> 결과 1건
하나씩 알아보자
1. 왼쪽 세션에서 트랜잭션을 시작하고 ‘자바의 정석 스터디’를 조회 >> 결과 0건
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM study WHERE name = '자바의 정석 스터디';
Empty set (0.00 sec)
2. 우측 세션에서 트랜잭션을 시작하고 이름이 ‘이펙티브 자바 스터디’를 ‘자바의 정석 스터디’로 변경하고 커밋
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> UPDATE study SET name = '자바의 정석 스터디' WHERE name = '이펙티브 자바 스터디';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> COMMIT;
3. 다시 왼쪽 세션에서 ‘자바의 정석 스터디’를 조회 >> 결과 1건
mysql> SELECT * FROM study WHERE name = '자바의 정석 스터디';
+----+--------------------+-----+
| id | name | max |
+----+--------------------+-----+
| 3 | 자바의 정석 스터디 | 7 |
+----+--------------------+-----+
1 row in set (0.00 sec)이전 조회와 달리 데이터가 일관되게 반환해야 한다는 REPEATABLE READ 정합성에 어긋나게 되는 문제가 생긴다.
이러한 부정합 현상은 하나의 트랜잭션에서 동일 데이터를 여러 번 읽고 변경하는 작업과 관련된 금전적인 처리와 함께한다면 문제가 될 수도 있다.
시나리오는 다음과 같다.
- B 트랜잭션에서 입금과 출금이 일어나고 있다.
- A 트랜잭션에서 1번 작업을 하는 사용자가 오늘 입금된 금액의 총합을 조회한다.
그런데 2번의 과정에서 NON-REPEATABLE READ 문제가 발생할 수 있기 때문에 조회 쿼리마다 다른 결과를 가져올 수도 있다.
REPEATABLE READ
REPEATABLE READ는 MySQL의 InnoDB 스토리지 엔진에서 기본적으로 사용되는 격리 수준으로 조회한 데이터 결과는 다시 조회해도 같은 결과를 반환한다.
MySQL :: MySQL 8.0 Reference Manual :: 15.7.2.1 Transaction Isolation Levels
15.7.2.1 Transaction Isolation Levels Transaction isolation is one of the foundations of database processing. Isolation is the I in the acronym ACID; the isolation level is the setting that fine-tunes the balance between performance and reliability, consi
dev.mysql.com
따라서 이전 격리 수준의 문제점이었던 NON-REPEATABLE READ 문제가 발생하지 않게 된다.
이것이 가능한 이유는 MVCC(Multi Version Concurrency Control) 변경 방식 덕분이다.
MVCC는 InnoDB 스토리지 엔진은 트랜잭션이 롤백될 가능성에 대비해 변경되기 전 레코드를 언두(Undo) 공간에 백업해두고 실제 레코드 값을 변경한다.
REPEATABLE READ는 이 MVCC를 위해 언두 영역에 백업된 이전 데이터를 이용해 동일 트랜잭션 내에서 동일한 결과를 보여주도록 보장한다.
모든 InnoDB의 트랜잭션은 순차적으로 증가하는 고유한 트랜잭션 번호를 가지게 되는데 변경이 발생하여 언두 영역에 백업되는 모든 레코드에 해당 트랜잭션 번호가 포함되게 된다.
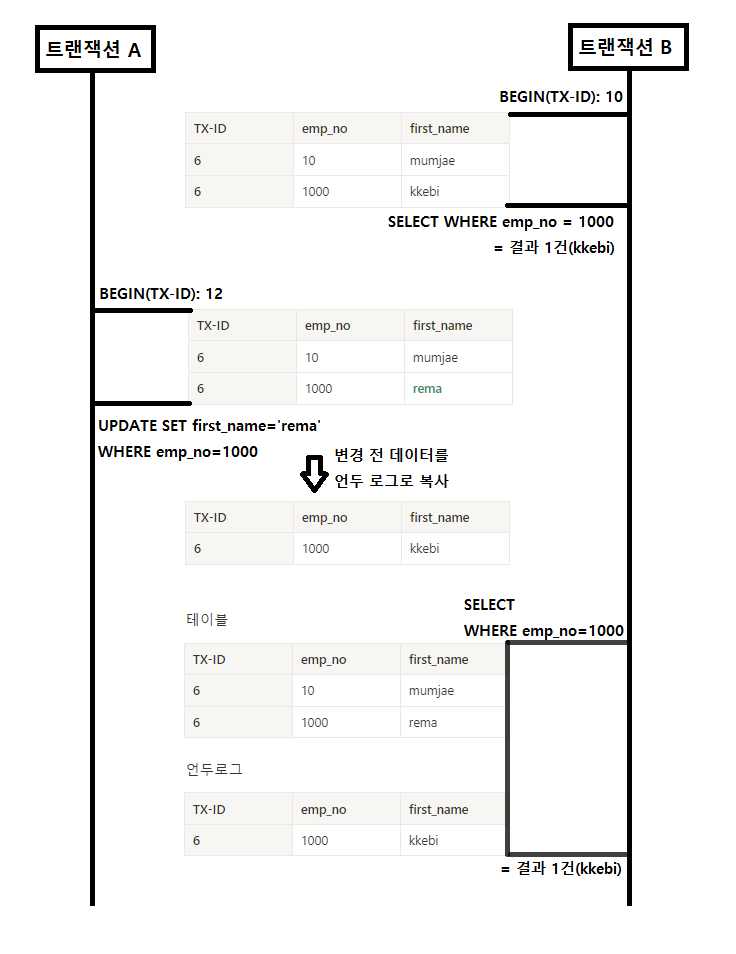
시나리오
1. 사전에 트랜잭션 번호 6번을 가진 트랜잭션이 두 개의 데이터를 추가
2. 트랜잭션 B(번호 10)에서 데이터를 조회
= 결과 1건(kkebi)
3. 트랜잭션 A(번호 12)에서 데이터를 변경
= 변경 전 데이터를 언두 로그에 기록
4. 트랜잭션 B(번호 10)에서 데이터를 조회
= 커밋이 되지 않은 경우 언두 영역의 데이터를 조회. 즉, 2번과 동일한 결과를 얻어옴
정리하면 트랜잭션 B가 트랜잭션을 시작하면서 트랜잭션 번호 10번을 부여받게 되는데 이때부터 트랜잭션 B안에서 실행되는 모든 SELECT 쿼리는 트랜잭션 번호가(자신의 트랜잭션 번호) 보다 작은 트랜잭션 번호에서 변경한 것만 보게 된다.
따라서 InnoDB에서 REPEATABLE READ에서는 NON-REPEATABLE READ 문제가 발생하지 않게 된다.
1. 두 개의 세션을 연결하고 각 세션을 REPEATABLE READ로 변경

2. 왼쪽 세션에서 트랜잭션을 시작하고 ‘Real MySQL 스터디’를 조회 >> 결과 0건
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM study WHERE name = 'Real MySQL 스터디';
Empty set (0.00 sec)
3. 우측 세션에서 트랜잭션을 시작하고 name이 ‘알고리즘 스터디’인 것을 ‘Real MySQL 스터디’로 변경하고 커밋
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> UPDATE study SET name = 'Real MySQL 스터디' WHERE name = '알고리즘 스터디';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> COMMIT;
4. 다시 왼쪽 세션에서 ‘자바의 정석 스터디’를 조회 >> 결과 0건
mysql> SELECT * FROM study WHERE name = 'Real MySQL 스터디';
Empty set (0.00 sec)
mysql> SELECT * FROM study WHERE name = 'Real MySQL 스터디';
Empty set (0.00 sec)
이처럼 조회한 데이터 결과는 다시 조회해도 같은 결과를 반환하게 된다.
REPEATABLE READ에서는 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다 안보였다 하는 현상인 PHANTOM READ 문제가 발생할 수 있다. 하지만 MySQL InnoDB에서는 MVCC(다중 버전 동시성 제어) 기능으로 인해 REPEATABLE READ 수준에서 PHANTOM READ가 발생하지 않는다.
⚡ More ⚡
Q. MySQL InnoDB에서 A와 B 트랜잭션을 실행시키고 A 트랜잭션에서 변경을 한 다음 B 트랜잭션에서 변경한 레코드를 조회하면 어디에 있는 데이터를 조회할까
A. 설정된 격리 수준에 따라 다르다.
- 격리 수준이 READ_UNCOMMITTED인 경우 InnoDB 버퍼 풀이 현재 가지고 있는 변경된 데이터를 읽어서 반환한다. 즉, 데이터가 커밋됐든 아니든 변경된 상태의 데이터를 반환한다.
- READ_COMMITTED나 그 이상의 격리 수준인 경우에는 아직 커밋되지 않았기 때문에 변경되지 이전의 내용을 보관하고 있는 언두 영역의 데이터를 반환한다.
이러한 과정을 DBMS에서는 MVCC라는 방식으로 표현한다.
⚡ More ⚡
Q. 격리 수준에 따른 문제인 PHANTOM READ와 NON-REPEATABLE READ는 유사해 보이는데 어떠한 차이가 있는 걸까?
NON-REPEATABLE READ
트랜잭션 과정 중에 행이 두 번 검색되고 행 내의 값이 읽기마다 다를 때 발생하는 문제
PHANTOM READ
트랜잭션 과정에서 두 개의 동일한 쿼리가 실행되고 두 번째 쿼리에서 반환된 행 컬렉션이 첫 번째 쿼리와 다를 때 발생하는 문제
SERIALIZABLE
가장 단순한 격리 수준이면서도 가장 엄격한 격리 수준인 SERIALIZABLE은 동시 처리 성능이 다른 트랜잭션 격리 수준에 비해 떨어진다.
트랜잭션 격리 수준이 SERIALIZABLE로 설정되면 읽기 작업도 공유 잠금(읽기 잠금)을 획득해야 하며 이는 다른 트랜잭션에서 동시에 해당 레코드를 변경할 수 없음을 의미한다. 즉, 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서는 절대 접근할 수 없게 된다.
SERIALIZABLE에서는 일반적인 DBMS에서 일어나는 PHANTOM READ라는 문제가 발생하지 않는다.
InnoDB 테이블에서 기본적으로 순수한 읽기 작업은 아무런 레코드 잠금도 설정하지 않고 실행(Non-locking consistnt read)되게 된다. 따라서 InnoDB 스토리지 엔진에서는 REPEATABLE READ 격리 수준에서도 PHANTOM READ가 발생하지 않기 때문에 굳이 SERIALIZABLE을 사용할 필요는 없다.
추가적인 학습 키워드
- MVCC(Multi Version Concurrency Control)
- 언두 로그, 리두 로그, 버퍼 풀
- 잠금 없는 일관된 읽기(Non-locking consistnt read)
번외로 트랜잭션 관점에서 스토리지 엔진인 MyISAM과 InnoDB는 동일하게 동작할까?
테이블 생성과 샘플 데이터 설정은 다음과 같다.
- testA: InnoDB, id가 3인 데이터 추가
- testB: MyISAM, id가 3인 데이터 추가
mysql> CREATE TABLE testA(
-> id INT NOT NULL,
-> PRIMARY KEY(id)
-> )ENGINE=INNODB;
Query OK, 0 rows affected (0.02 sec)
mysql> CREATE TABLE testB(
-> id INT NOT NULL,
-> PRIMARY KEY(id)
-> )ENGINE=MyISAM;
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO testA(id) VALUES(3);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO testB(id) VALUES(3);
Query OK, 1 row affected (0.01 sec)
위와 같은 상태로 오토 커밋을 킨 상태로 각 테이블에 1,2,3 값을 추가하는 쿼리를 실행한다.
mysql> SET AUTOCOMMIT = 1;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES WHERE VARIABLE_NAME = 'AUTOCOMMIT';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.01 sec)
mysql> INSERT INTO testA(id) VALUES(1), (2), (3);
ERROR 1062 (23000): Duplicate entry '3' for key 'testa.PRIMARY'
mysql> INSERT INTO testB(id) VALUES(1), (2), (3);
ERROR 1062 (23000): Duplicate entry '3' for key 'testb.PRIMARY'당연하게도 두 문장 모두 기본 키 중복 오류로 인해 에러가 발생하게 된다.
그런데 testA(InnoDB)와 testB(MyISAM) 테이블을 조회하게 되면 다음과 같은 결과를 반환하게 된다.
mysql> SELECT * FROM testA;
+----+
| id |
+----+
| 3 |
+----+
1 row in set (0.00 sec)
mysql> SELECT * FROM testB;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
+----+
3 rows in set (0.00 sec)- InnoDB는 쿼리 중 일부라도 오류가 발생하면 전체를 원 상태로 만든다는 트랜잭션의 원칙에 맞게 INSERT 쿼리를 실행하기 전 상태로 복구(ROLLBACK)한다.
- MyISAM은 이러한 부분 업데이트(Partial Update)라는 문제가 발생하여 데이터의 정합성을 맞추는데 어려움이 존재한다. 만약 MyISAM에서 실패에 대한 재처리 작업을 해야 한다면 레코드를 INSERT 할 때 IF ELSE문으로 처리를 해주어야 한다.
참고
- MySQL 공식문서
- 인프런 스프링 DB 1편
- Real MySQL 8.0
'DB' 카테고리의 다른 글
| [DB] 클러스터형 인덱스와 세컨더리 인덱스 그리고 활용(커버링 인덱스) (0) | 2023.07.15 |
|---|---|
| [DB] 이진 탐색 트리부터 B+Tree까지 그리고 인덱스 - 1 (0) | 2023.02.22 |

